Pertemuan 5#
Data mentah dalam Data Mining sering kali memiliki skala atribut yang sangat timpang karena awalnya dirancang untuk kebutuhan operasional, bukan analisis. Ketimpangan ini dapat mendistorsi hasil algoritma yang berbasis perhitungan jarak, di mana atribut bernilai besar akan mendominasi atribut kecil secara tidak proporsional. Untuk mengatasinya, diperlukan teknik Normalisasi Data—seperti Min-Max Normalization, Z-Score, atau Decimal Scaling—yang mentransformasi nilai ke dalam skala seragam tanpa menghilangkan informasi esensial, sehingga memastikan setiap atribut memberikan kontribusi yang adil dalam proses pemodelan.
Z-Score Normalization#
Z-Score Normalization atau sering disebut standardisasi merupakan metode normalisasi yang mengubah distribusi data sehingga memiliki nilai rata-rata sebesar 0 dan standar deviasi sebesar 1. Dengan cara ini, data akan memiliki distribusi yang lebih seimbang sehingga memudahkan proses analisis.
Metode ini biasanya digunakan ketika nilai minimum atau maksimum suatu atribut tidak diketahui secara pasti, atau ketika dataset mengandung outlier yang dapat memengaruhi skala data jika menggunakan metode normalisasi lain seperti Min-Max.
Rumus Z-Score \(v' = \frac{v - \bar{A}}{\sigma_A}\)
Keterangan
v = nilai asli data
v’ = nilai hasil normalisasi
Ā = rata-rata dari atribut A
σA = standar deviasi atribut A
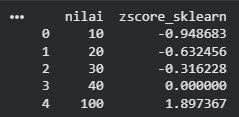
Sebagai contoh, misalkan terdapat data: [10, 20, 30, 40, 100], Nilai 100 dapat dianggap sebagai outlier.
Hasil perhitungan:
Rata-rata = 40
Standar deviasi ≈ 31.62
Hasil Normalisasi
10 => -0.94
40 => 0.00
100 => 1.89 Nilai 0 menunjukkan bahwa data berada tepat pada nilai rata-rata.
import pandas as pd
from sklearn.preprocessing import StandardScaler
# membuat dataset contoh
data = {'nilai': [10, 20, 30, 40, 100]}
df = pd.DataFrame(data)
# membuat objek scaler
scaler = StandardScaler()
# melakukan normalisasi Z-score
df['zscore_sklearn'] = scaler.fit_transform(df[['nilai']])
# menampilkan hasil
print(df)
Min-Max Normalization#
Min-Max Normalization merupakan metode normalisasi yang bertujuan untuk mengubah nilai atribut numerik ke dalam rentang tertentu, biasanya 0 sampai 1. Teknik ini sering digunakan agar semua atribut memiliki skala yang sebanding.
Metode ini banyak digunakan pada algoritma yang berbasis perhitungan jarak, seperti K-Nearest Neighbors, karena tanpa normalisasi atribut dengan nilai yang lebih besar dapat mendominasi hasil perhitungan.
Rumus Min-Max Normalization \(v' = \frac{v - min_A}{max_A - min_A} (new\_max_A - new\_min_A) + new\_min_A\)
Jika rentang yang digunakan adalah 0 sampai 1, maka rumusnya dapat disederhanakan menjadi: \(v' = \frac{v - min_A}{max_A - min_A}\)
Keterangan
v = nilai asli data
v’ = nilai setelah normalisasi
minA = nilai minimum pada atribut A
maxA = nilai maksimum pada atribut A
new_minA = batas bawah rentang baru
new_maxA = batas atas rentang baru
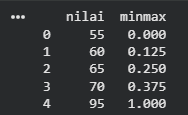
Contoh data: [10, 20, 30, 40, 100]
Nilai minimum = 10
Nilai maksimum = 100
Hasil Normalisasi
10 => -0.0
40 => 0.33
100 => 1.0
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# membuat dataset contoh
data = {'nilai': [55, 60, 65, 70, 95]}
df = pd.DataFrame(data)
# membuat objek scaler
scaler = MinMaxScaler()
# melakukan normalisasi
df['minmax'] = scaler.fit_transform(df[['nilai']])
# membulatkan 3 angka di belakang koma
df['minmax'] = df['minmax'].round(3)
# menampilkan hasil
print(df)
Decimal Scaling#
Decimal Scaling merupakan metode normalisasi yang dilakukan dengan cara menggeser posisi titik desimal pada nilai data. Proses ini dilakukan dengan membagi nilai atribut dengan pangkat sepuluh tertentu.
Tujuan dari metode ini adalah agar nilai absolut maksimum dari atribut menjadi lebih kecil dari 1.
Rumus Decimal Scaling \(v' = \frac{v}{10^j}\)
Keterangan
v = nilai asli data
v’ = nilai setelah normalisasi
j = bilangan bulat terkecil yang membuat nilai maksimum atribut menjadi kurang dari 1 Nilai j biasanya ditentukan dari jumlah digit angka terbesar dalam atribut.
Contoh data: [10, 20, 30, 40, 100]
Nilai terbesar = 100 Jumlah digit = 3
Sehingga semua nilai dibagi dengan 10³ (1000).
Hasil normalisasi:
10 => 0.01
40 => 0.04
100 => 0.10
import pandas as pd
import numpy as np
# dataset contoh
data = {'nilai': [10, 20, 30, 40, 100]}
df = pd.DataFrame(data)
# mencari nilai maksimum
max_val = df['nilai'].abs().max()
# menentukan nilai j
j = len(str(int(max_val)))
# melakukan decimal scaling
df['decimal_scaling'] = df['nilai'] / (10**j)
# membulatkan hasil
df['decimal_scaling'] = df['decimal_scaling'].round(3)
print(df)
Missing Value Imputation Menggunakan Weighted K-Nearest Neighbor (WKNN)#
Pengertian Missing Value#
Dalam proses pengolahan data, sering dijumpai situasi di mana beberapa atribut tidak memiliki nilai atau datanya tidak tersedia. Kondisi ini dikenal sebagai missing value. Missing value dapat muncul karena berbagai alasan, seperti kesalahan dalam pencatatan data, data yang tidak berhasil dikumpulkan, atau hilangnya data selama proses penyimpanan.
Jika missing value tidak ditangani dengan tepat, maka hasil analisis data yang diperoleh dapat menjadi kurang akurat atau bahkan menyesatkan. Oleh karena itu, diperlukan suatu metode untuk memperkirakan atau mengisi nilai yang hilang tersebut agar data dapat digunakan secara optimal dalam proses analisis.
Salah satu metode yang dapat digunakan untuk menangani permasalahan ini adalah Weighted K-Nearest Neighbor (WKNN), yaitu teknik yang memperkirakan nilai yang hilang berdasarkan kedekatan data dengan data lain yang memiliki karakteristik serupa.
Konsep Weighted K-Nearest Neighbor (WKNN)#
Metode WKNN merupakan pengembangan dari algoritma K-Nearest Neighbor (KNN). Pada pendekatan ini, nilai yang hilang diperkirakan dengan mempertimbangkan data lain yang memiliki tingkat kemiripan paling tinggi dengan data yang sedang dianalisis.
Perbedaan utama antara KNN standar dan WKNN terletak pada penerapan bobot (weight). Dalam WKNN, setiap data tetangga tidak memberikan pengaruh yang sama. Data yang memiliki jarak lebih dekat dengan data target akan memperoleh bobot yang lebih besar, sedangkan data yang jaraknya lebih jauh akan memiliki pengaruh yang lebih kecil.
Secara umum, tahapan dalam metode WKNN meliputi:
Melakukan normalisasi data agar setiap atribut berada pada skala yang sebanding.
Menghitung jarak antara data target dengan data lainnya.
Menentukan bobot berdasarkan nilai jarak yang telah dihitung.
Mengestimasi nilai yang hilang menggunakan perhitungan rata-rata tertimbang.
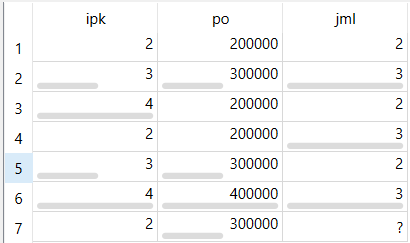
Dataset#
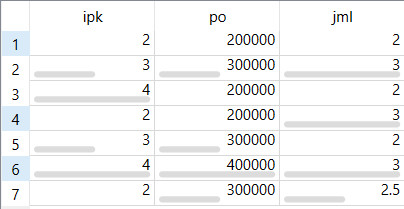
Dataset yang digunakan terdiri dari tiga atribut yaitu IPK, PO, dan JML.
No |
IPK |
PO |
JML |
|---|---|---|---|
1 |
2 |
2000000 |
2 |
2 |
3 |
3000000 |
3 |
3 |
4 |
2000000 |
2 |
4 |
2 |
2000000 |
3 |
5 |
3 |
3000000 |
2 |
6 |
4 |
4000000 |
3 |
7 |
2 |
3000000 |
? |
Pada baris ke-7 nilai JML belum diketahui. Nilai tersebut akan diperkirakan menggunakan metode WKNN.
Perhitungan secara manual#
Tahap 1 – Normalisasi Data#
Karena nilai atribut IPK dan PO memiliki skala yang berbeda, maka data perlu dinormalisasi terlebih dahulu menggunakan metode Min-Max Normalization.
Rumus yang digunakan: x’ = (x - min) / (max - min)
Rumus Excel untuk normalisasi IPK: =(A2-MIN(\(A\)2:\(A\)8))/(MAX(\(A\)2:\(A\)8)-MIN(\(A\)2:\(A\)8))
Rumus Excel untuk normalisasi PO: =(B2-MIN(\(B\)2:\(B\)8))/(MAX(\(B\)2:\(B\)8)-MIN(\(B\)2:\(B\)8))
Hasil normalisasi data ditunjukkan pada tabel berikut.
No |
IPK |
PO |
JML |
|---|---|---|---|
1 |
0 |
0 |
0 |
2 |
0.5 |
0.5 |
1 |
3 |
1 |
0 |
0 |
4 |
0 |
0 |
1 |
5 |
0.5 |
0.5 |
0 |
6 |
1 |
1 |
1 |
7 |
0 |
0.5 |
? |
Baris ke-7 merupakan data target yang nilai JML-nya akan diprediksi.
Tahap 2 – Menghitung Selisih Nilai#
Langkah berikutnya menghitung selisih antara nilai normalisasi setiap data dengan nilai data target.
Contoh rumus Excel untuk selisih IPK: =F2-\(F\)8
Contoh rumus Excel untuk selisih PO: =G2-\(G\)8
Tahap 3 – Menghitung Kuadrat Selisih#
Selisih yang diperoleh kemudian dikuadratkan untuk mendapatkan komponen jarak.
Contoh rumus Excel: =K2^2
Tahap 4 – Menghitung Bobot#
Setelah jarak diperoleh, langkah berikutnya adalah menentukan bobot setiap tetangga menggunakan rumus: w = 1 / (jarak²)
Rumus Excel: =1/(L2+N2)
Semakin kecil jarak antara data dengan data target, maka bobotnya akan semakin besar.
Tahap 5 – Menghitung Pembilang#
Pembilang dihitung dengan mengalikan bobot dengan nilai JML dari setiap data tetangga.
Rumus Excel: =P2*C2
Berikut Tabel Perhitungan WKNN
No |
Selisih IPK |
Kuadrat IPK |
Selisih PO |
Kuadrat PO |
Bobot |
Pembilang |
|---|---|---|---|---|---|---|
1 |
0 |
0 |
-0.5 |
0.25 |
4 |
8 |
2 |
0.5 |
0.25 |
0 |
0 |
4 |
12 |
3 |
1 |
1 |
-0.5 |
0.25 |
0.8 |
1.6 |
4 |
0 |
0 |
-0.5 |
0.25 |
4 |
12 |
5 |
0.5 |
0.25 |
0 |
0 |
4 |
8 |
6 |
1 |
1 |
0.5 |
0.25 |
0.8 |
2.4 |
Tahap 6 – Menghitung Estimasi Nilai#
Setelah semua nilai diperoleh, langkah terakhir adalah menghitung estimasi nilai menggunakan weighted average.
Total pembilang: =SUM(Q2:Q7)
Total bobot: =SUM(P2:P7)
Perkiraan nilai JML dihitung dengan rumus: =Total Pembilang / Total Bobot
Jadi hasil estimasi yang diperoleh adalah: JML ≈ 2.5
Perhitungan secara Code / Orange#
Untuk mempermudah proses tersebut tanpa perlu menyusun rumus di Excel secara manual satu per satu, dapat digunakan script Python melalui widget Python Script pada aplikasi Orange. Dengan cara ini, proses pengolahan data dapat dilakukan secara otomatis.
Script yang digunakan memanfaatkan pustaka scikit-learn untuk melakukan proses normalisasi data. Selain itu, script tersebut juga mampu menangani data dengan jumlah kolom maupun baris yang memiliki nilai kosong secara otomatis, sehingga proses pengisian missing value dapat dilakukan dengan lebih efisien.
import numpy as np
import pandas as pd
from Orange.data.pandas_compat import table_to_frame, table_from_frame
from sklearn.preprocessing import MinMaxScaler
if in_data is not None:
# 1. Mengubah data dari format Orange menjadi Pandas DataFrame
df = table_to_frame(in_data)
# Mendeteksi secara otomatis kolom yang memiliki tipe numerik
numeric_cols = df.select_dtypes(include=[np.number]).columns
df_calc = df[numeric_cols].copy()
# 2. Melakukan normalisasi menggunakan metode Min-Max dari sklearn
scaler = MinMaxScaler()
df_calc[numeric_cols] = scaler.fit_transform(df_calc[numeric_cols])
# 3. Tahap imputasi missing value dengan metode WKNNI
# Mengidentifikasi baris yang memiliki minimal satu nilai kosong (NaN)
baris_kosong = df[df.isnull().any(axis=1)].index
for idx in baris_kosong:
kolom_kosong = df.columns[df.loc[idx].isnull()]
for target_col in kolom_kosong:
if target_col not in numeric_cols:
continue
# Memilih kandidat tetangga yang memiliki nilai pada kolom target
tetangga_idx = df[df[target_col].notnull()].index
if len(tetangga_idx) == 0:
continue
# Menentukan fitur yang dapat digunakan untuk menghitung jarak
fitur_tersedia = df_calc.columns[df_calc.loc[idx].notnull()]
fitur_jarak = [c for c in fitur_tersedia if c != target_col]
if len(fitur_jarak) == 0:
continue
target_features = df_calc.loc[idx, fitur_jarak]
tetangga_features = df_calc.loc[tetangga_idx, fitur_jarak]
# Menghitung jarak serta bobot kemiripan antar data
jarak_kuadrat = np.nansum((tetangga_features - target_features)**2, axis=1)
bobot = 1 / (jarak_kuadrat + 1e-10) # nilai kecil untuk mencegah pembagian nol
# Menghitung estimasi nilai menggunakan weighted average
nilai_tetangga = df.loc[tetangga_idx, target_col]
estimasi = np.sum(bobot * nilai_tetangga) / np.sum(bobot)
# Mengisi kembali nilai yang hilang pada dataset
df.loc[idx, target_col] = round(estimasi, 2)
print(f"Baris ke-{idx + 1}, Kolom '{target_col}' diestimasi: {round(estimasi, 2)}")
# 4. Mengonversi kembali DataFrame ke format tabel Orange
out_data = table_from_frame(df)
Alur di Orange
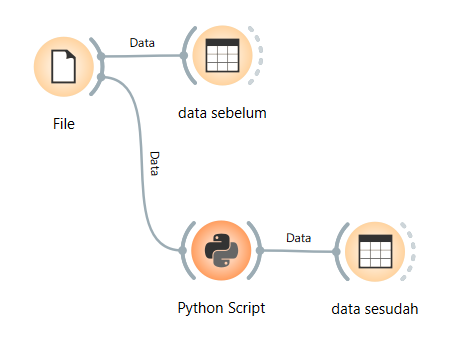
Hasil Sebelum
Hasil Sesudah