Pertemuan 2#
Eksplorasi Data pada Dataset Iris#
1. Pendahuluan#
Eksplorasi data merupakan tahap awal yang sangat penting dalam proses penambangan data. Tahap ini bertujuan untuk memahami karakteristik data sebelum dilakukan analisis lanjutan seperti klasifikasi, clustering, atau prediksi. Dengan melakukan eksplorasi data, peneliti dapat mengetahui struktur data, pola sebaran, variasi nilai, serta potensi permasalahan seperti outlier atau data ekstrem.
Pada tugas ini digunakan dataset Iris, yaitu dataset klasik yang sering dijadikan contoh dalam bidang data mining dan machine learning. Dataset ini dipilih karena memiliki struktur yang sederhana namun cukup representatif untuk menjelaskan konsep eksplorasi data dan visualisasi.
2. Deskripsi Dataset#
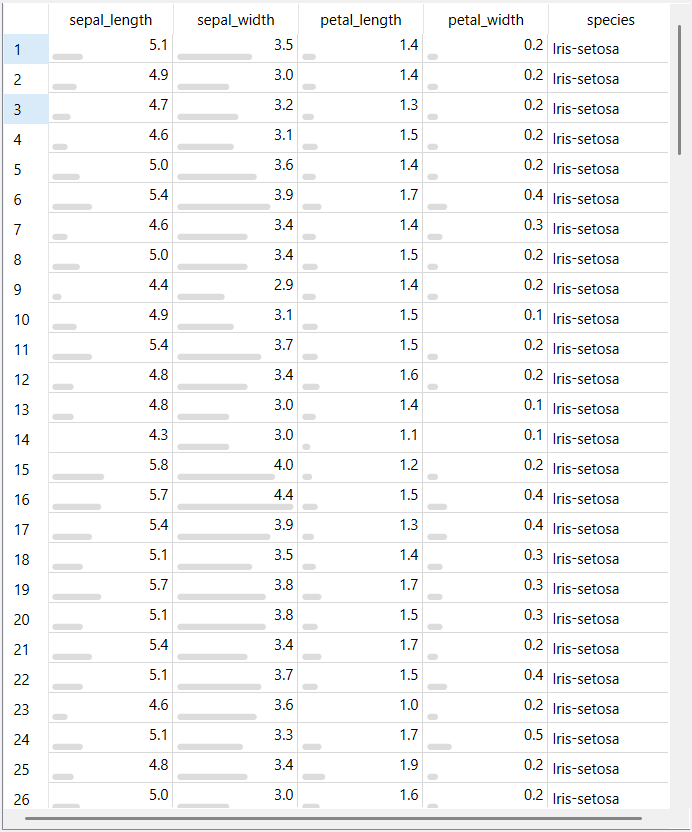
Dataset Iris terdiri dari 150 data observasi yang merepresentasikan bunga iris. Setiap data memiliki empat atribut numerik, yaitu:
Sepal Length: panjang kelopak luar bunga
Sepal Width: lebar kelopak luar bunga
Petal Length: panjang mahkota bunga
Petal Width: lebar mahkota bunga
Keempat atribut tersebut digunakan untuk menggambarkan karakteristik fisik bunga iris. Data bersifat numerik dan tidak memiliki nilai kosong, sehingga dataset dapat langsung digunakan untuk analisis statistik dan visualisasi tanpa tahap pembersihan data yang kompleks.
3. Statistik Deskriptif#
Statistik deskriptif digunakan untuk memberikan gambaran umum mengenai data melalui ukuran pemusatan dan penyebaran, seperti nilai rata-rata, median, nilai minimum, maksimum, dan standar deviasi.
Atribut |
Min |
Max |
Mean |
Median |
Std Dev |
|---|---|---|---|---|---|
Sepal Length |
4.3 |
7.9 |
5.84 |
5.80 |
0.83 |
Sepal Width |
2.0 |
4.4 |
3.05 |
3.00 |
0.43 |
Petal Length |
1.0 |
6.9 |
3.76 |
4.35 |
1.76 |
Petal Width |
0.1 |
2.5 |
1.20 |
1.30 |
0.76 |
Berdasarkan tabel di atas, dapat diketahui bahwa atribut petal length memiliki standar deviasi terbesar, yaitu 1.76, yang menunjukkan variasi data yang tinggi. Atribut petal width juga memiliki variasi yang cukup besar. Sebaliknya, atribut sepal width memiliki standar deviasi paling kecil, yaitu 0.43, yang menandakan bahwa data pada atribut ini relatif homogen.
Hasil statistik deskriptif ini menunjukkan bahwa atribut petal memiliki variasi yang lebih besar dibandingkan atribut sepal, sehingga berpotensi lebih informatif dalam proses analisis data.
4. Visualisasi Data#
4.1 Scatter Plot Sepal Length dan Sepal Width#
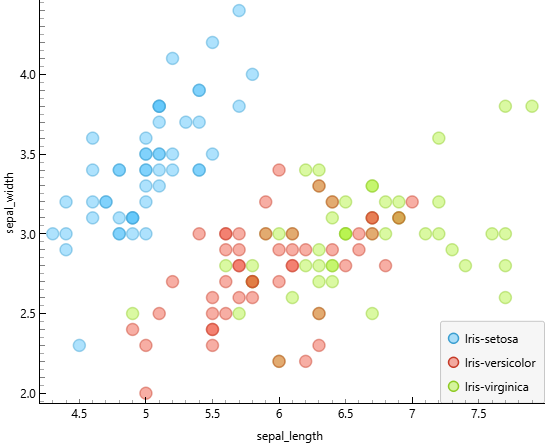
Scatter plot antara sepal length dan sepal width digunakan untuk melihat hubungan antara dua atribut sepal. Berdasarkan visualisasi, titik-titik data terlihat menyebar dan tidak membentuk pola linear yang jelas.
Sebaran data yang acak menunjukkan bahwa hubungan antara sepal length dan sepal width tergolong lemah. Perubahan nilai sepal length tidak diikuti secara konsisten oleh perubahan sepal width. Oleh karena itu, kombinasi kedua atribut sepal ini kurang efektif jika digunakan sebagai penentu utama dalam membedakan karakteristik data bunga iris.
4.2 Scatter Plot Petal Length dan Petal Width#
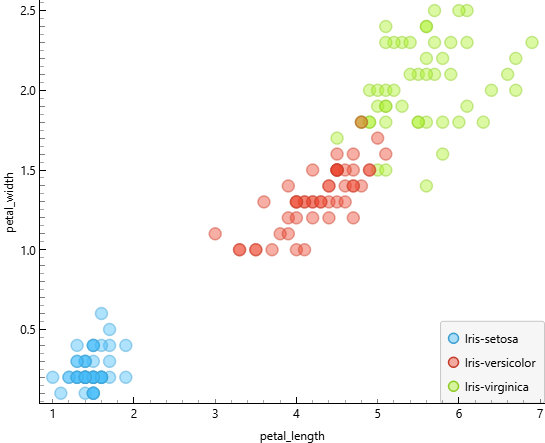
Scatter plot antara petal length dan petal width menunjukkan pola yang berbeda dibandingkan atribut sepal. Titik-titik data terlihat lebih rapat dan membentuk kecenderungan linear positif.
Hal ini menunjukkan bahwa terdapat hubungan yang kuat antara petal length dan petal width, di mana semakin panjang mahkota bunga, semakin lebar ukurannya. Selain itu, terlihat adanya pola pengelompokan data yang cukup jelas, yang menandakan bahwa atribut petal sangat informatif dalam membedakan karakteristik data bunga iris.
5. Analisis Korelasi Berdasarkan Scatter Plot#
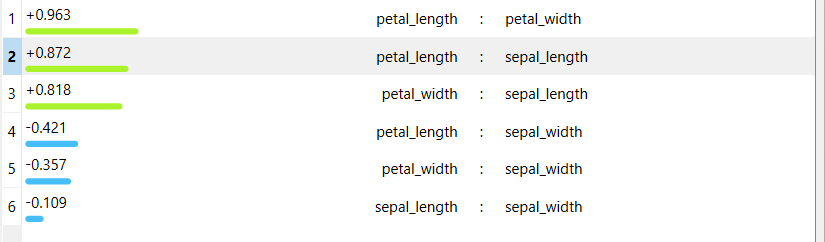
Analisis korelasi pada tugas ini dilakukan secara visual menggunakan scatter plot. Interpretasi korelasi didasarkan pada pola sebaran data, bukan pada nilai numerik koefisien korelasi.
Berdasarkan scatter plot sepal length dan sepal width, korelasi antar atribut sepal terlihat lemah karena sebaran data tidak membentuk pola yang terarah. Sebaliknya, scatter plot petal length dan petal width menunjukkan hubungan yang kuat dan positif, ditandai dengan sebaran data yang lebih rapat dan membentuk kecenderungan linear.
Perbedaan pola ini menunjukkan bahwa hubungan antar atribut petal lebih kuat dibandingkan hubungan antar atribut sepal.
6. Kesimpulan#
Berdasarkan hasil eksplorasi data, statistik deskriptif, visualisasi, dan analisis korelasi, dapat disimpulkan bahwa dataset Iris memiliki struktur data yang baik dan siap digunakan untuk analisis lanjutan.
Atribut petal length dan petal width memiliki variasi data yang tinggi serta hubungan yang kuat, sehingga menjadi atribut utama dalam analisis dataset Iris. Sementara itu, atribut sepal, khususnya sepal width, memiliki hubungan yang lemah dan peran yang lebih terbatas dalam membedakan data.